

Which Of The Following Transformations Is Most Useful For Correcting Skewed Data?
Top 3 Methods for Handling Skewed Data
Real-world data can be messy. Even some learning datasets contain attributes that demand astringent modifications before they tin be used to do predictive modeling.
And that's fine.
Permit'southward take a linear regression model for case. You probably know this already, but the model makes a skilful corporeality of assumptions for the information you provide, such as:
- Linearity: assumes that the relationship betwixt predictors and target variable is linear
- No dissonance: eg. that there are no outliers in the data
- No collinearity: if you have highly correlated predictors, it'due south nearly likely your model will overfit
- Normal distribution: more reliable predictions are made if the predictors and the target variable are normally distributed
- Calibration: it's a distance-based algorithm, so preditors should be scaled — similar with standard scaler
That'due south quite a lot for a elementary model. Today I want to focus on the 4th signal, and that is that predictors and target variable should follow a gaussian distribution.
Now that's non always quite possible to do, ergo you cannot transform whatever distribution into a perfect normal distribution, merely that doesn't mean you shouldn't effort.
To offset out, allow'south load a uncomplicated dataset and practice the magic.
The Dataset
I volition use the familiar Boston Housing Prices dataset to explore some techniques of dealing with skewed data.
There's no need to download it, as you can import information technology straight from Scikit-larn. Here'southward the lawmaking with all the imports and dataset loading:
Upon execution the get-go couple of rows volition be shown, you should have the same output as I do:

I don't want to explore all of the variables equally I've done some tests before and concluded that the variable CRIMhas the highest skew. Here's the code to verify my claim:

Cool. At present y'all can utilise the Seaborn library to make a histogram alongside with the KDE plot to run across what nosotros're dealing with:

This certainly doesn't follow a normal distribution. And yep, if yous're wondering how I shifted from awful-looking default visualization, here's an article yous should read:
Okay, at present when we take that covered, let's explore some methods for handling skewed data.
1. Log Transform
Log transformation is most likely the starting time thing you lot should exercise to remove skewness from the predictor.
Information technology can exist hands done via Numpy, merely by calling the log() part on the desired column. You tin then only as easily check for skew:

And just like that, we've gone from the skew coefficient of 5.ii to 0.iv. Only earlier jumping to conclusions we should likewise make a quick visualization:
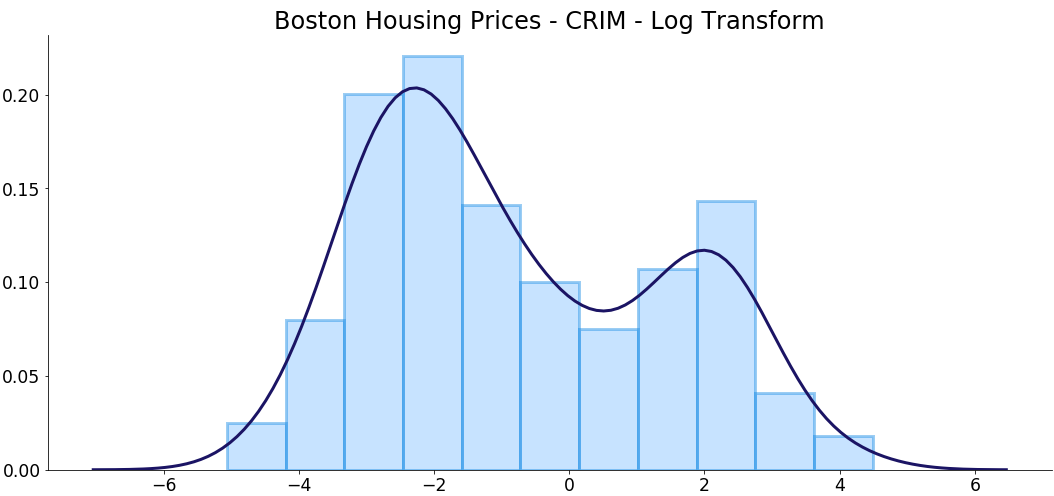
Well, it'due south not commonly distributed for sure, but is a lot better than what we had before!
Every bit you would expect, the log transformation isn't the just one you tin can use. Permit'south explore a couple of more than options.
2. Square Root Transform
The foursquare root sometimes works great and sometimes isn't the best suitable option. In this case, I nevertheless expect the transformed distribution to await somewhat exponential, just just due to taking a square root the range of the variable will be smaller.
You can apply a square root transformation via Numpy, past calling the sqrt() office. Here's the lawmaking:

The skew coefficient went from five.2 to 2, which still is a notable difference. However, the log transformation ended with ameliorate results.
Nevertheless, let's visualize how everything looks at present:
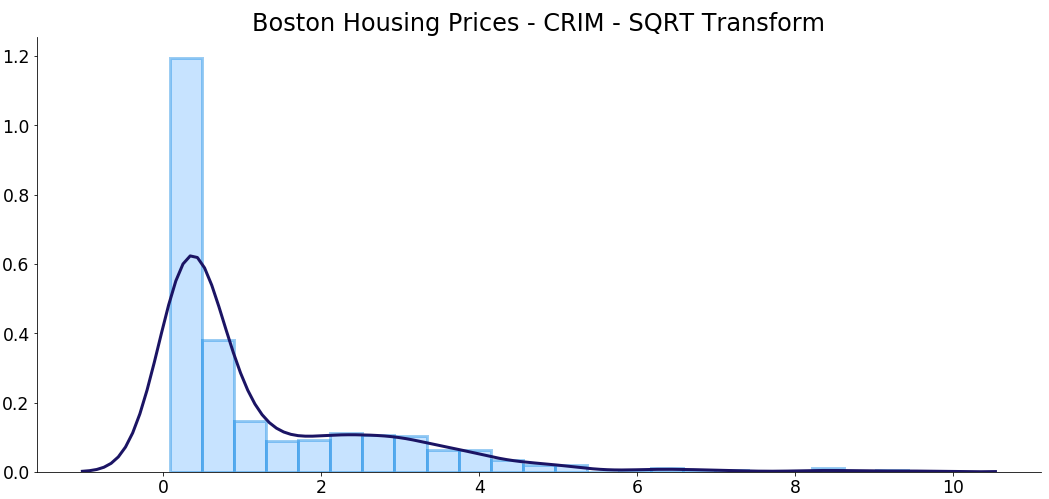
The distribution is pretty much the same, but the range is smaller, as expected.
Before declaring the log transformation every bit the winner, let's explore one more.
3. Box-Cox Transform
This is the last transformation method I want to explore today. Equally I don't desire to drill down into the math behind, hither's a short article for anyone interested in that role.
You should just know that information technology is just some other way of treatment skewed data. To utilise information technology, your data must be positive — so that can be a bummer sometimes.
You lot tin import it from the Scipy library, simply the check for the skew you'll need to convert the resulting Numpy array to a Pandas Series:

Wow! The skew dropped from 5.2 to 0.09 but. Still, let'due south meet how the transformed variable looks like:
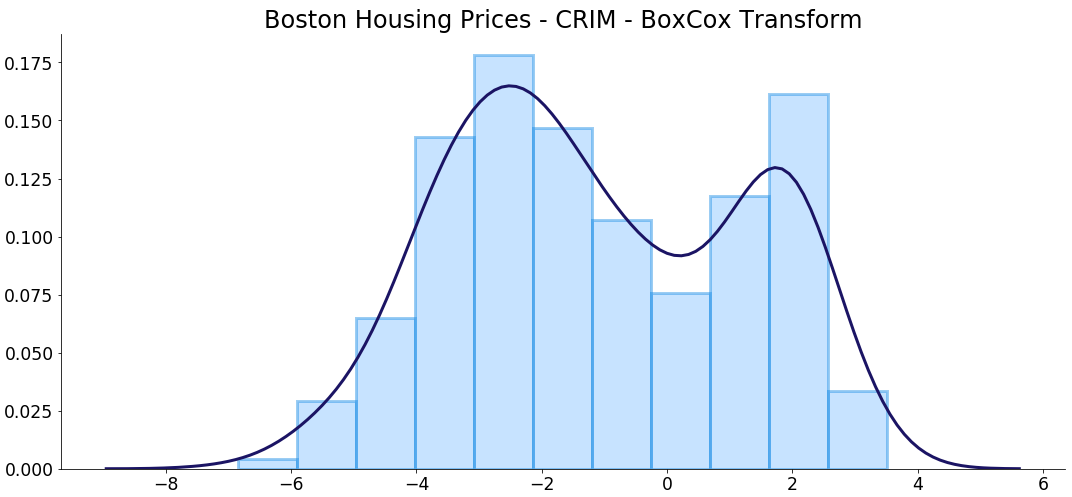
The distribution is pretty similar to the one made past the log transformation, but just a touch less bimodal I would say.
Before yous go
Skewed data can mess up the power of your predictive model if you don't address it correctly.
This should go without saying, but you should call up what transformation you've performed on which aspect, because you'll take to contrary it in one case when making predictions, and then go along that in listen.
Nevertheless, these three methods should accommodate you lot well.
What transformation methods are you using? Please let me know.
Loved the article? Become a Medium fellow member to continue learning without limits. I'll receive a portion of your membership fee if yous use the following link, with no actress cost to you.

Which Of The Following Transformations Is Most Useful For Correcting Skewed Data?,
Source: https://towardsdatascience.com/top-3-methods-for-handling-skewed-data-1334e0debf45
Posted by: whiteleyanyther.blogspot.com
0 Response to "Which Of The Following Transformations Is Most Useful For Correcting Skewed Data?"
Post a Comment